

人工智能在图像生成领域的创新步伐从未停歇。近日,Hugging Face平台上线了一款名为VisualCloze的全新工具,以其独特的视觉上下文学习(Visual In-Context Learning)技术,标志着通用图像生成框架的又一重大突破。AIbase通过整理社交媒体上的动态,深入剖析这一工具的亮点与潜力,为读者带来手报道。
VisualCloze亮相:通用图像生成的全新范式
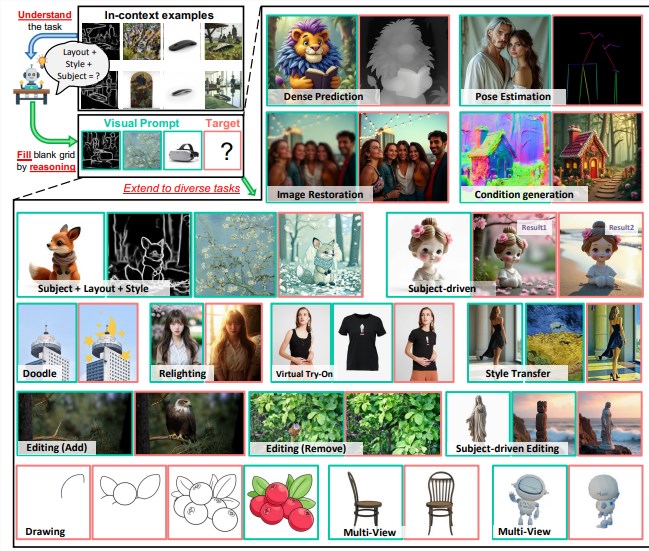
VisualCloze作为Hugging Face的开源项目,旨在通过视觉上下文学习实现高度灵活的图像生成。不同于传统的图像生成模型,VisualCloze能够基于少量示例图像,在无需额外微调的情况下,快速适应多种生成任务。这种
“即学即用”
的能力使其在多样化场景中展现出强大的通用性,涵盖从艺术创作到产品设计等广泛应用。
AIbase了解到,VisualCloze的核心理念是将语言模型的上下文学习能力迁移到视觉领域。用户只需提供少量参考图像作为“上下文”,即可引导模型生成符合特定风格、主题或结构的图像。这种方法不仅简化了创作流程,还显著降低了技术门槛。
技术亮点:视觉上下文学习的突破
VisualCloze的独特之处在于其视觉上下文学习框架。通过对输入图像的智能解析,模型能够捕捉关键的视觉特征,并在生成过程中保持高度一致性。社交媒体上,创作者们分享了使用VisualCloze生成的多样化作品,从复古插图到未来主义建筑,展示了其在风格迁移和细节还原上的出色表现。
此外,VisualCloze支持多模态输入,允许用户结合文本描述和图像示例,进一步提升生成结果的精准度。例如,输入一张草图并搭配“赛博朋克城市夜景”的描述,VisualCloze即可生成符合预期的复杂场景。这种灵活性使其在广告设计、游戏开发等领域具有广阔的应用前景。
开源生态赋能:Hugging Face的持续创新
作为Hugging Face平台的新成员,VisualCloze延续了该平台一贯的开源精神。开发者可以自由访问模型代码、数据集和文档,快速将其集成到自己的项目中。AIbase注意到,VisualCloze的发布引发了社区的热烈讨论,许多开发者表示计划基于该框架开发定制化工具,进一步扩展其功能。Hugging Face的开源生态为VisualCloze提供了强大的支持。无论是模型优化还是社区反馈,都将推动这一框架不断进化。AIbase认为,这种开放协作的模式正是VisualCloze能够在短时间内吸引广泛关注的关键。
未来展望:重塑图像创作的可能性
VisualCloze的发布不仅是技术上的突破,更是对图像生成领域创作范式的重新定义。其
低门槛
、
高灵活性
的特点,让从专业设计师到普通用户都能轻松参与到高质量内容创作中。AIbase预计,未来VisualCloze可能进一步融入视频生成、3D建模等方向,为多模态创作带来更多可能性。与此同时,VisualCloze的通用性也为行业带来了新的思考:如何在保持创意自由的同时,确保生成内容的伦理性和原创性?AIbase将持续关注这一工具的发展动态,为读者带来更多深度分析。
结语:VisualCloze开启创作新纪元
VisualCloze的推出为图像生成领域注入了新的活力,其视觉上下文学习技术为创作者提供了前所未有的灵活性和效率。AIbase相信,这款工具将在Hugging Face的开源生态中不断成长,成为AI驱动创作的重要里程碑。
项目地址:
© 版权声明
本文转载自互联网、仅供学习交流,内容版权归原作者所有,如涉作品、版权或其它疑问请联系AIbaiku导航或点击删除。
相关文章




