《敏感词过滤技巧全解析:应对策略与实战经验》
在当今数字化时代,敏感词过滤已成为网络平台、社交媒体以及各类信息传播渠道中不可或缺的一部分。它不仅关乎到用户的信息安全和平台的合规性,还涉及到如何在保护合法言论的同时,防止违法不良信息的扩散。因此,掌握敏感词过滤的技巧不仅是技术问题,更是一种社会责任。本文将从敏感词过滤的基本概念入手,探讨其重要性,并深入分析当前常见的敏感词过滤方法,同时结合实际案例分享一些实用的应对策略。
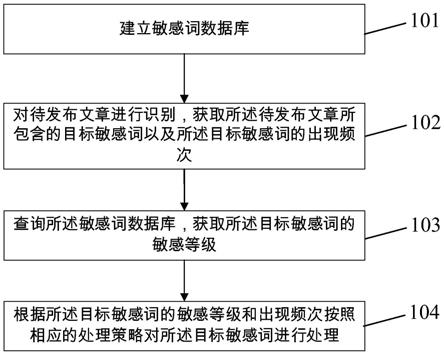
一、敏感词过滤的概念与意义
敏感词过滤是指通过特定的技术手段识别出可能引起争议或违反法律法规的词汇,并对其进行处理的过程。这里的“敏感”不仅仅指政治上的敏感,还包括但不限于宗教、文化、社会等各个领域内的敏感话题。敏感词过滤的意义在于:
-
保障网络安全:防止恶意攻击者利用敏感词进行网络攻击或传播有害信息。
-
维护社会稳定:避免因不当言论引发的社会矛盾和不稳定因素。
-
促进健康和谐的网络环境:为用户提供一个积极向上、文明健康的交流空间。
二、常见的敏感词过滤方法
为了实现有效的敏感词过滤,通常会采用以下几种方法:
(一)关键词匹配法
这是最基础也是最常见的敏感词过滤方式之一。通过对已知敏感词库中的每一个单词进行逐一比对,当输入的内容包含这些关键词时,系统就会触发相应的处理机制。这种方法存在一定的局限性,例如:
-
容易出现误报现象:由于语言的多样性,有时候简单的字面意思可能会导致正常表达被错误地认定为敏感词。
-
无法应对变体形式:随着人们创造能力的发展,新的变体形式不断涌现,这使得传统的关键词匹配法难以跟上变化的步伐。
(二)语义分析法
相较于单纯的关键词匹配,语义分析法更加注重理解上下文之间的关系,从而提高过滤的准确性。它能够识别出那些看似无关但实际具有潜在危险性的词汇组合,如“某明星出轨”这样的表述。不过,语义分析也面临着挑战:
-
计算资源消耗大:为了准确地进行语义分析,往往需要投入大量的计算资源来训练模型,这对于一些小型企业来说可能是一个不小的负担。
-
语义理解的复杂性:自然语言处理领域本身就是一个充满挑战的研究方向,如何让机器更好地理解和解释人类的语言仍然是一个未解之谜。
(三)机器学习算法
近年来,随着人工智能技术的进步,越来越多的企业开始尝试使用机器学习算法来进行敏感词过滤。这种方法的核心思想是基于历史数据来构建分类器,然后利用这个分类器对新出现的数据进行预测。尽管取得了显著成效,但也存在一些不足之处:
-
数据依赖性强:要想获得良好的效果,必须要有足够量且高质量的历史数据作为训练样本,否则模型可能会出现过拟合或者欠拟合的情况。
-
更新周期较长:由于需要定期收集新的数据并对模型进行重新训练,所以在面对快速变化的网络环境时,机器学习算法可能会显得有些滞后。
三、敏感词过滤中的常见问题及解决办法
在实际应用过程中,我们经常会遇到各种各样的问题,下面列举几个典型例子并提出相应的解决方案:
(一)如何避免误报?
误报是指那些实际上并没有问题却被错误地标记为敏感词的情况。为了避免这种情况的发生,可以从以下几个方面着手:
-
建立完善的敏感词库:确保所使用的敏感词库既全面又准确,尽量涵盖所有可能出现的敏感词汇及其变体形式。
-
引入人工审核机制:对于那些疑似敏感但不确定是否真的属于敏感范畴的内容,可以由专业人员进行复核,以减少误报率。
-
动态调整规则:根据实际情况的变化,及时更新敏感词库和相关规则,使系统能够与时俱进地适应新的情况。
(二)怎样应对漏报?
漏报则是指那些确实存在敏感内容却没有被正确识别出来的情况。要解决这个问题,可以采取以下措施:
-
优化算法模型:通过改进现有的机器学习算法或者采用更先进的深度学习框架,提升系统的准确率。
-
增加正面词汇库:除了关注负面词汇外,还可以适当加入一些正面词汇,以便更好地区分不同类型的文本。
-
加强用户反馈机制:鼓励广大网民积极参与进来,及时向平台反映存在的问题,以便于我们不断地改进和完善。
四、敏感词过滤的未来发展趋势
随着科技的不断发展,敏感词过滤也将迎来更多的机遇和挑战。展望未来,我们可以预见以下几个趋势:
-
智能化程度不断提高:借助于云计算、大数据等新兴技术的支持,未来的敏感词过滤系统将会变得更加智能高效。
-
跨平台协作日益紧密:不同类型的网络平台之间将加强合作,共同制定统一的标准和规范,以确保整个互联网生态系统的健康发展。
-
法律监管力度持续加大:政府相关部门将进一步加强对敏感词过滤工作的指导和支持,促使各行业遵守相关法律法规的要求。
敏感词过滤是一项复杂而又重要的工作,需要我们不断地探索创新,才能在这个瞬息万变的时代里始终保持领先地位。希望本文所提供的信息能够帮助大家更好地理解和运用这一技术,在推动科技进步的同时也为构建清朗网络空间做出贡献。
















发表评论